
Aelius is an ongoing free software, open source project aiming at developing a suite of Python, NLTK-based modules and interfaces to external freely available tools for shallow parsing of Brazilian Portuguese. It also includes resources such as language models, sample texts, and gold standards. Presently, Aelius offers facilities for tokenizing and POS-tagging corpora using a variety of tokenization strategies and tagsets, outputting annotations in different formats, such as in XML in the TEI P5 encoding scheme. A common interface to the following non-Python taggers is already implemented, extending NLTK, which provides interfaces only to the first two taggers:
A basic nominal chunker for the LX-Tagger tagset is also available.
This guide presents Aelius main capabilities and resources for tokenizing, morpho-syntactically annotating and chunking texts in Portuguese. Several practical recipes in form of individual commands and code snippets to execute interactively on the Python shell demonstrate how to perform these tasks.
In the following, I assume you are running the Python IDLE shell in an unixoid operating system like Mac OS X, Linux, etc or in an Unix-like environment under Windows. Text files should use Unix line breaks (LF character) and unicode utf-8 is assumed as the default file encoding, since both have become standard in corpus lnguistics. In order to execute the different commands in this tutorial, some familiarity with Python, the IDLE shell, the Unix shell and the Unix file system is recquired. Reading the first five chapters of the NLTK book is also strongly recommended:
Bird, S., Klein, E., & Loper, E. (2009). Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit. Sebastopol, CA: O'Reilly.
You don't need in-depth programming skills, though. Everything you need to know for annotating corpora with Aelius can be learned in a two weeks crash course.
Aelius mainly targets native speakers or students and researches of Portuguese. For this reason, the names of most modules, functions, classes, variables, etc. are in Portuguese, as it is most of the documentation embedded in the Python source code, which together constitutes a detailed user's guide. But since some of Aelius facilities are not specific to Portuguese and can be used to annotate texts in other languages with NLTK and non-Python external tools, the present guide is written in English in order to reach potential users with insufficient, if any, reading skills in Portuguese.
The first version of Aelius was presented at the following conference, whose proceedings will hopefully be published soon; a draft of the presentation is available on-line:
Alencar, Leonel Figueiredo de. Aelius: uma ferramenta para anotação automática de corpora usando o NLTK. ELC 2010, The 9th Brazilian Corpus Linguistics Meeting, Porto Alegre, Brazil, Rio Grande do Sul Catholic University (PUCRS), October 8 and 9, 2010.
The following paper deals with the present version of Aelius:
ALENCAR, L. F. de. Novos recursos do Aelius para o processamento computacional raso do português. In: LAPORTE, E.; SMARSARO, A.; VALE, O. (Eds.) Dialogar é preciso: linguística para o processamento de línguas. 1 ed. Vitória: PPGEL/UFES, 2013, p. 7-20.
For more example commands and for keeping updated with publications related to Aelius, please visit the CompLin blog (in Portuguese):
If you use Aelius, either the Python package itself or the corresponding language data (models, corpora, etc.) belonging to the distribution, in your research, you should cite accordingly. This is mandatory for any specialized software available on the Internet, as stated, for example, by Purdue Onnline Writing Lab [http://owl.english.purdue.edu/owl/resource/560/10/], which recommends the format below, based on APA.
If you use language data from the Aelius distribution based on third-party resources, such as a language model trained on a specific corpus, you should also cite the third-party resource accordingly. Please refer to the README file in the aelius_data folder for detailed information on these resources.
Please consult the __init__.py file in the Aelius folder or print the Aelius.__version__ variable in the Python or IDLE shell for obtaining the version number and release year of your Aelius installation:
Alencar, L. F. de. (2013). Aelius Brazilian Portuguese POS-Tagger and Corpus Annotation Tool (Version 0.9.7) [Software]. Available from http://aelius.sourceforge.net.
Alencar, Leonel Figueiredo de. Aelius Brazilian Portuguese POS-Tagger and Corpus Annotation Tool, versão 0.9.7. Fortaleza: [s.n.], 2013. Disponível em: <http://aelius.sourceforge.net/>. Acesso em: 25 fev. 2013.
Presently, Aelius only works with version 2.0.1rc1 of NLTK, which you can download from here. I reccomend you install NLTK 2.0.1rc1 from source. I assume you have properly installed this version under Python 2.7 and the recquired additional Python libraries: PyYAML, NumPy, and Matplotlib.
If you have at least basic knowledge of Python and the Unix shell, and have some experience with free, open source command-line tools, installing Aelius and its external tools is quite straightfoward: Just put the Aelius subfolder of the unzipped downloaded folder in a place where Python can find it (for example, by including the respective path in your PYTHONPATH environment variable) and the aelius_data subfolder in your home directory. As for the external, non-Python libraries and executables, install them according to the respective installing instructions. You should include the paths to the Java jar files in your CLASSPATH environment variable, and the paths to external binaries in your PATH environment variable.
For people who are less familiar with typical free, open source software used in computational linguistics, here is a step-by-step guide:
In sum, you should include the following lines into your .profile or .bash_profile file:
# path to MXPOST jar file
CLASSPATH="$HOME/jmx/mxpost.jar"
export CLASSPATH
# path to MXPOST binary
PATH="${PATH}:$HOME/jmx"
export PATH
# path to HunPos binaries
PATH="${PATH}:$HOME/Applications/bin"
export PATH
# path to Aelius package
PYTHONPATH="${PYTHONPATH}:$HOME/Applications"
export PYTHONPATH
# path to Stanford Tagger jar file (eventually, update the version date or the
# folder name to the one of your installed version)
CLASSPATH="${CLASSPATH}:$HOME/stanford-postagger-2012-11-11/stanford-postagger.jar"
export CLASSPATH
# eventually, update the version date or the
# folder name to the one of your installed version
CLASSPATH="${CLASSPATH}:$HOME/apache-opennlp-1.5.2-incubating/lib/opennlp-tools.jar"
export CLASSPATH
PATH="${PATH}:$HOME/apache-opennlp-1.5.2-incubating/bin/"
export PATH
For detailed installation instructions in Portuguese, see INSTALL file.
| Model | Training corpus | Architecture | Programming language |
| AeliusRUBT.pkl | Tycho Brahe Parsed Corpus of Historical Portuguese | NLTK | Python |
| AeliusBRUBT.pkl | Tycho Brahe Parsed Corpus of Historical Portuguese | NLTK | Python |
| AeliusHunPos | Tycho Brahe Parsed Corpus of Historical Portuguese | HunPos | OCaml |
| AeliusMaxEnt | Tycho Brahe Parsed Corpus of Historical Portuguese | MXPOST | Java |
| AeliusHunPosMM | MAC-Morpho | HunPos | OCaml |
| AeliusStanfordMM | MAC-Morpho | Stanford Log-linear Part-Of-Speech Tagger | Java |
| AeliusMaxEntMM | MAC-Morpho | MXPOST | Java |
| AeliusPerceptronOpenNLP.bin | MAC-Morpho | Apache OpenNLP | Java |
| AeliusMaxentOpenNLP.bin | MAC-Morpho | Apache OpenNLP | Java |
For information on the tag-sets used by the models distributed with Aelius, visit the homepages of the respective training corpora:
Tycho Brahe Parsed Corpus of Historical Portuguese(TBCHP) [http://www.tycho.iel.unicamp.br/~tycho/corpus/en/index.html].
Reference:
GALVES, C.; FARIA,
P. Tycho Brahe Parsed Corpus of Historical Portuguese. [S.l.: s.n.],
2010. On-line:
<http://www.tycho.iel.unicamp.br/~tycho/corpus/en/index.html>
MAC-MORPHO Corpus of Brazilian Portuguese (version prepared for tagger training [http://www.nilc.icmc.usp.br/lacioweb/macmorpho.php] and adapted for distribution with NLTK). This corpus is part of the Lácio-WebProject [http://www.nilc.icmc.usp.br/lacioweb/index.htm].
Na Europa e nos Estados Unidos, a área da Linguística Computacional está em extrema expansão e goza de muita popularidade, tanto nos cursos de Ciências da Computação quanto nos de Linguística. De fato, o estudo do processamento automático da linguagem natural é considerado nesses países como relevante não só para a indústria de software, mas também para a elaboração de teorias gramaticais formalmente consistentes e psicolinguisticamente realistas. (ALENCAR, Leonel Figueiredo de; OTHERO, Gabriel de Ávila. Abordagens computacionais da teoria da gramática. Campinas: Mercado de Letras, 2012, p. 9-10.)
>>> from Aelius import Toqueniza
>>> t="""Na Europa e nos Estados Unidos, a área da Linguística Computacional está em extrema expansão e goza de muita popularidade, tanto nos cursos de Ciências da Computação quanto nos de Linguística. De fato, o estudo do processamento automático da linguagem natural é considerado nesses países como relevante não só para a indústria de software, mas também para a elaboração de teorias gramaticais formalmente consistentes e psicolinguisticamente realistas."""
>>> t=t.decode("utf-8")
>>> sents=Toqueniza.PUNKT.tokenize(t)
>>> for sent in sents:
for token in Toqueniza.TOK_PORT.tokenize(sent):
print "%s" % token
print
Na
Europa
e
nos
Estados
Unidos
,
a
área
da
Linguística
Computacional
está
em
extrema
expansão
e
goza
de
muita
popularidade
,
tanto
nos
cursos
de
Ciências
da
Computação
quanto
nos
de
Linguística
.
De
fato
,
o
estudo
do
processamento
automático
da
linguagem
natural
é
considerado
nesses
países
como
relevante
não
só
para
a
indústria
de
software
,
mas
também
para
a
elaboração
de
teorias
gramaticais
formalmente
consistentes
e
psicolinguisticamente
realistas
.

>>> from Aelius import AnotaCorpus, Toqueniza >>> sent=AnotaCorpus.EXEMPLO >>> sent u'Os candidatos classific\xe1veis dos cursos de Sistemas de Informa\xe7\xe3o poder\xe3o ocupar as vagas remanescentes do Curso de Engenharia de Software.' >>> print sent Os candidatos classificáveis dos cursos de Sistemas de Informação poderão ocupar as vagas remanescentes do Curso de Engenharia de Software. >>> tokens=Toqueniza.TOK_PORT.tokenize(sent) >>> tokens [u'Os', u'candidatos', u'classific\xe1veis', u'dos', u'cursos', u'de', u'Sistemas', u'de', u'Informa\xe7\xe3o', u'poder\xe3o', u'ocupar', u'as', u'vagas', u'remanescentes', u'do', u'Curso', u'de', u'Engenharia', u'de', u'Software', u'.'] >>> m=AnotaCorpus.TAGGER2 >>> t=AnotaCorpus.anota_sentencas([tokens],AnotaCorpus.TAGGER2) >>> t [[(u'Os', u'D-P'), (u'candidatos', u'N-P'), (u'classific\xe1veis', u'ADJ-G-P'), (u'dos', u'P+D-P'), (u'cursos', u'N-P'), (u'de', u'P'), (u'Sistemas', u'NPR-P'), (u'de', u'P'), (u'Informa\xe7\xe3o', u'NPR'), (u'poder\xe3o', u'VB-R'), (u'ocupar', u'VB'), (u'as', u'D-F-P'), (u'vagas', u'ADJ-F-P'), (u'remanescentes', u'ADJ-G-P'), (u'do', u'P+D'), (u'Curso', u'NPR'), (u'de', u'P'), (u'Engenharia', u'NPR'), (u'de', u'P'), (u'Software', u'NPR'), (u'.', u'.')]] >>> for w,t in t[0]: print "%s\%s " % (w,t), Os\D-P candidatos\N-P classificáveis\ADJ-G-P dos\P+D-P cursos\N-P de\P Sistemas\NPR-P de\P Informação\NPR poderão\VB-R ocupar\VB as\D-F-P vagas\ADJ-F-P remanescentes\ADJ-G-P do\P+D Curso\NPR de\P Engenharia\NPR de\P Software\NPR .\. >>>
>>> from Aelius import Extras
>>> t=Extras.carrega("exemplo.txt")
>>> type(t)
<type 'str'>
>>> t
'/Users/leonel/aelius_data/exemplo.txt'
>>> import os
>>> os.path.expanduser("~")
'/Users/leonel'
>>> print open(t,"rU").read()[:444]
O excerto abaixo contém os dois primeiros parágrafos do romance "Luzia-Homem" (Rio de Janeiro, 1903), de Domingos Olímpio, nascido em Sobral, Ceará, em 18 de setembro de 1850 e falecido no Rio de Janeiro em 6 de outubro de 1906. O texto, extraído do site Wikisource, foi revisado por Leonel F. de Alencar.
O morro do Curral do Açougue emergia em suave declive da campina ondulada. Escorchado, indigente de arvoredo, o cômoro enegrecido
>>> linhas=open(t,"rU").readlines()
>>> print linhas[0]
O excerto abaixo contém os dois primeiros parágrafos do romance "Luzia-Homem" (Rio de Janeiro, 1903), de Domingos Olímpio, nascido em Sobral, Ceará, em 18 de setembro de 1850 e falecido no Rio de Janeiro em 6 de outubro de 1906. O texto, extraído do site Wikisource, foi revisado por Leonel F. de Alencar.
>>> linhas[1]
'\n'
>>> linhas[2]
'O morro do Curral do A\xc3\xa7ougue emergia em suave declive da campina ondulada. Escorchado, indigente de arvoredo, o c\xc3\xb4moro enegrecido pelo sangue de reses sem conto, deixara de ser o s\xc3\xadtio sinistro do matadouro e a pousada predileta de bandos de urubutingas e camirangas vorazes. \n'
>>> para2=linhas[2].decode("utf-8")
>>> para2
u'O morro do Curral do A\xe7ougue emergia em suave declive da campina ondulada. Escorchado, indigente de arvoredo, o c\xf4moro enegrecido pelo sangue de reses sem conto, deixara de ser o s\xedtio sinistro do matadouro e a pousada predileta de bandos de urubutingas e camirangas vorazes. \n'
>>> from Aelius import Toqueniza, AnotaCorpus
>>> sents=Toqueniza.PUNKT.tokenize(para2)
>>> len(sents)
2
>>> listas_de_tokens=[Toqueniza.TOK_PORT.tokenize(s) for s in sents]
>>> listas_de_tokens
[[u'O', u'morro', u'do', u'Curral', u'do', u'A\xe7ougue', u'emergia', u'em', u'suave', u'declive', u'da', u'campina', u'ondulada', u'.'], [u'Escorchado', u',', u'indigente', u'de', u'arvoredo', u',', u'o', u'c\xf4moro', u'enegrecido', u'pelo', u'sangue', u'de', u'reses', u'sem', u'conto', u',', u'deixara', u'de', u'ser', u'o', u's\xedtio', u'sinistro', u'do', u'matadouro', u'e', u'a', u'pousada', u'predileta', u'de', u'bandos', u'de', u'urubutingas', u'e', u'camirangas', u'vorazes', u'.']]
>>> sentencas_anotadas=AnotaCorpus.anota_sentencas(listas_de_tokens,AnotaCorpus.TAGGER2)
>>> for s in sentencas_anotadas:
for w,t in s:
print "%s_%s" % (w,t)
print
O_D
morro_N
do_P+D
Curral_NPR
do_P+D
Açougue_NPR
emergia_VB-D
em_P
suave_ADJ-G
declive_N
da_P+D-F
campina_N
ondulada_VB-AN-F
._.
Escorchado_VB-AN
,_,
indigente_ADJ-G
de_P
arvoredo_N
,_,
o_D
cômoro_N
enegrecido_VB-AN
pelo_P+D
sangue_N
de_P
reses_N-P
sem_P
conto_N
,_,
deixara_VB-RA
de_P
ser_SR
o_D
sítio_N
sinistro_N
do_P+D
matadouro_N
e_CONJ
a_D-F
pousada_N
predileta_ADJ-F
de_P
bandos_N-P
de_P
urubutingas_N-P
e_CONJ
camirangas_N-P
vorazes_ADJ-G-P
._.
>>> import os
>>> from Aelius import Extras, Toqueniza, AnotaCorpus
>>> t=Extras.carrega("exemplo.txt")
>>> raiz,nome=os.path.split(t)
>>> AnotaCorpus.anota_texto(nome,raiz=raiz)
Arquivo anotado:
exemplo.nltk.txt
>>> import nltk
>>> leitor_de_corpus=nltk.corpus.TaggedCorpusReader(".","exemplo.nltk.txt")
>>> leitor_de_corpus.tagged_sents()[0]
[('O', 'D'), ('excerto', 'N'), ('abaixo', 'ADV'), ('cont\xc3\xa9m', 'VB-P'), ('os', 'D-P'), ('dois', 'NUM'), ('primeiros', 'ADJ-P'), ('par\xc3\xa1grafos', 'N-P'), ('do', 'P+D'), ('romance', 'N'), ('"', 'QT'), ('Luzia', 'P'), ('-', '+'), ('Homem', 'NPR'), ('"', 'QT'), ('(', '('), ('Rio', 'NPR'), ('de', 'P'), ('Janeiro', 'NPR'), (',', ','), ('1903', 'NUM'), (')', '('), (',', ','), ('de', 'P'), ('Domingos', 'NPR'), ('Ol\xc3\xadmpio', 'NPR'), (',', ','), ('nascido', 'VB-AN'), ('em', 'P'), ('Sobral', 'NPR'), (',', ','), ('Cear\xc3\xa1', 'NPR'), (',', ','), ('em', 'P'), ('18', 'NUM'), ('de', 'P'), ('setembro', 'NPR'), ('de', 'P'), ('1850', 'NUM'), ('e', 'CONJ'), ('falecido', 'VB-PP'), ('no', 'P+D'), ('Rio', 'NPR'), ('de', 'P'), ('Janeiro', 'NPR'), ('em', 'P'), ('6', 'NUM'), ('de', 'P'), ('outubro', 'NPR'), ('de', 'P'), ('1906', 'NUM'), ('.', '.')]
>>> len(leitor_de_corpus.tagged_paras())
3
>>> leitor_de_corpus.sents()[0]
['O', 'excerto', 'abaixo', 'cont\xc3\xa9m', 'os', 'dois', 'primeiros', 'par\xc3\xa1grafos', 'do', 'romance', '"', 'Luzia', '-', 'Homem', '"', '(', 'Rio', 'de', 'Janeiro', ',', '1903', ')', ',', 'de', 'Domingos', 'Ol\xc3\xadmpio', ',', 'nascido', 'em', 'Sobral', ',', 'Cear\xc3\xa1', ',', 'em', '18', 'de', 'setembro', 'de', '1850', 'e', 'falecido', 'no', 'Rio', 'de', 'Janeiro', 'em', '6', 'de', 'outubro', 'de', '1906', '.']
>>>
>>> import os
>>> os.chdir(os.path.expanduser("~/analises"))
>>> t="actg.txt"
>>> AnotaCorpus.anota_texto(t)
Arquivo anotado:
actg.nltk.txt
>>>
>>> from Aelius import AnotaCorpus, Extras
>>> r=Extras.carrega("AeliusRUBT.pkl")
>>> rubt=AnotaCorpus.abre_etiquetador(r)
>>> rubt
<TrigramTagger: size=16001>
>>> from Aelius import ProcessaNomesProprios
>>> sents=ProcessaNomesProprios.SENTENCAS
>>> for sent in sents:
print sent
– Luzia pediu a Deus e a Ávila para que lhe ajudassem a sair de Sobral .
Deus ajudou Luzia .
... Sobral era uma cidade intelectual .
... Cidade intelectual , Sobral tinha muitos poetas .
Município intelectual , Sobral tinha muitos poetas .
Fortaleza era uma cidade provinciana .
Ávila ajudou Luzia .
... Cansada , Luzia logo dormiu .
Ávida por sossego , Luzia deixou a cidade .
Ótimo !
Bom .
... – Bom .
?
! ? ? –
>>> tokens=[sent.split() for sent in sents]
>>> tokens[0]
[u'\u2013', u'Luzia', u'pediu', u'a', u'Deus', u'e', u'a', u'\xc1vila', u'para', u'que', u'lhe', u'ajudassem', u'a', u'sair', u'de', u'Sobral', u'.']
>>> rubt.tag(tokens[0])
[(u'\u2013', 'N'), (u'Luzia', 'NPR'), (u'pediu', 'VB-D'), (u'a', 'P'), (u'Deus', 'NPR'), (u'e', 'CONJ'), (u'a', 'D-F'), (u'\xc1vila', 'N'), (u'para', 'P'), (u'que', 'WPRO'), (u'lhe', 'CL'), (u'ajudassem', 'VB-SD'), (u'a', 'D-F'), (u'sair', 'VB'), (u'de', 'P'), (u'Sobral', 'NPR'), (u'.', '.')]
>>> rubt.tag(tokens[3])
[(u'...', '.'), (u'Cidade', 'NPR'), (u'intelectual', 'ADJ-G'), (u',', ','), (u'Sobral', 'NPR'), (u'tinha', 'TR-D'), (u'muitos', 'Q-P'), (u'poetas', 'N-P'), (u'.', '.')]
>>> for s in AnotaCorpus.anota_sentencas(tokens[:-3],r):
for w,t in s:
print "%s/%s " % (w,t),
print
–/( Luzia/NPR pediu/VB-D a/P Deus/NPR e/CONJ a/D-F Ávila/NPR para/P que/WPRO lhe/CL ajudassem/VB-SD a/D-F sair/VB de/P Sobral/NPR ./.
Deus/NPR ajudou/VB-D Luzia/NPR ./.
.../. Sobral/NPR era/SR-D uma/D-UM-F cidade/N intelectual/ADJ-G ./.
.../. Cidade/N intelectual/ADJ-G ,/, Sobral/NPR tinha/TR-D muitos/Q-P poetas/N-P ./.
Município/N intelectual/ADJ-G ,/, Sobral/NPR tinha/TR-D muitos/Q-P poetas/N-P ./.
Fortaleza/N era/SR-D uma/D-UM-F cidade/N provinciana/ADJ-F ./.
Ávila/NPR ajudou/VB-D Luzia/NPR ./.
.../. Cansada/VB-AN-F ,/, Luzia/NPR logo/ADV dormiu/VB-D ./.
Ávida/VB-AN-F por/P sossego/N ,/, Luzia/NPR deixou/VB-D a/P cidade/N ./.
Ótimo/ADJ !/.
Bom/ADJ ./.
.../. –/( Bom/ADJ ./.
>>> for s in rubt.batch_tag(tokens[:-3]):
for w,t in s:
print "%s/%s " % (w,t),
print
–/N Luzia/NPR pediu/VB-D a/P Deus/NPR e/CONJ a/D-F Ávila/N para/P que/WPRO lhe/CL ajudassem/VB-SD a/D-F sair/VB de/P Sobral/NPR ./.
Deus/NPR ajudou/VB-D Luzia/NPR ./.
.../. Sobral/NPR era/SR-D uma/D-UM-F cidade/N intelectual/ADJ-G ./.
.../. cidade/N intelectual/ADJ-G ,/, Sobral/NPR tinha/TR-D muitos/Q-P poetas/N-P ./.
município/N intelectual/ADJ-G ,/, Sobral/NPR tinha/TR-D muitos/Q-P poetas/N-P ./.
fortaleza/N era/SR-D uma/D-UM-F cidade/N provinciana/ADJ-F ./.
Ávila/N ajudou/VB-D Luzia/NPR ./.
.../. cansada/VB-AN-F ,/, Luzia/NPR logo/ADV dormiu/VB-D ./.
ávida/N por/P sossego/N ,/, Luzia/NPR deixou/VB-D a/P cidade/N ./.
ótimo/N !/.
bom/ADJ ./.
.../. –/N bom/ADJ ./.
>>> tokens=[sent.split() for sent in sents]
>>> for s in rubt.batch_tag(tokens[:-3]):
for w,t in s:
print "%s/%s " % (w,t),
print
–/N Luzia/NPR pediu/VB-D a/P Deus/NPR e/CONJ a/D-F Ávila/N para/P que/WPRO lhe/CL ajudassem/VB-SD a/D-F sair/VB de/P Sobral/NPR ./.
Deus/NPR ajudou/VB-D Luzia/NPR ./.
.../. Sobral/NPR era/SR-D uma/D-UM-F cidade/N intelectual/ADJ-G ./.
.../. Cidade/NPR intelectual/ADJ-G ,/, Sobral/NPR tinha/TR-D muitos/Q-P poetas/N-P ./.
Município/NPR intelectual/ADJ-G ,/, Sobral/NPR tinha/TR-D muitos/Q-P poetas/N-P ./.
Fortaleza/N era/SR-D uma/D-UM-F cidade/N provinciana/ADJ-F ./.
Ávila/N ajudou/VB-D Luzia/NPR ./.
.../. Cansada/VB-AN-F ,/, Luzia/NPR logo/ADV dormiu/VB-D ./.
Ávida/N por/P sossego/N ,/, Luzia/NPR deixou/VB-D a/P cidade/N ./.
Ótimo/N !/.
Bom/ADJ ./.
.../. –/N Bom/NPR ./.
>>>
>>> from Aelius import AnotaCorpus
>>> from Aelius import ProcessaNomesProprios
>>> sents=ProcessaNomesProprios.SENTENCAS
>>> tokens=[sent.split() for sent in sents]
>>> codificadas=AnotaCorpus.codifica_sentencas(tokens)
>>> for s in rubt.batch_tag(codificadas[:-3]):
for w,t in s:
print "%s/%s " % (w,t),
print
–/( Luzia/NPR pediu/VB-D a/P Deus/NPR e/CONJ a/D-F Ávila/NPR para/P que/WPRO lhe/CL ajudassem/VB-SD a/D-F sair/VB de/P Sobral/NPR ./.
Deus/NPR ajudou/VB-D Luzia/NPR ./.
.../. Sobral/NPR era/SR-D uma/D-UM-F cidade/N intelectual/ADJ-G ./.
.../. Cidade/NPR intelectual/ADJ-G ,/, Sobral/NPR tinha/TR-D muitos/Q-P poetas/N-P ./.
Município/NPR intelectual/ADJ-G ,/, Sobral/NPR tinha/TR-D muitos/Q-P poetas/N-P ./.
Fortaleza/N era/SR-D uma/D-UM-F cidade/N provinciana/ADJ-F ./.
Ávila/NPR ajudou/VB-D Luzia/NPR ./.
.../. Cansada/VB-AN-F ,/, Luzia/NPR logo/ADV dormiu/VB-D ./.
Ávida/N por/P sossego/N ,/, Luzia/NPR deixou/VB-D a/P cidade/N ./.
Ótimo/N !/.
Bom/ADJ ./.
.../. –/( Bom/ADJ ./.
>>> s="Não sei se está funcionando .".decode("utf-8")
>>> rubt.tag(s.split())
[(u'N\xe3o', 'NPR'), (u'sei', 'VB-P'), (u'se', 'WQ'), (u'est\xe1', 'N'), (u'funcionando', 'VB-G'), (u'.', '.')]
>>> AnotaCorpus.codifica_sentencas([s.split()])
[['N\xc3\xa3o', 'sei', 'se', 'est\xc3\xa1', 'funcionando', '.']]
>>> codificada=AnotaCorpus.codifica_sentencas([s.split()])
>>> codificada
[['N\xc3\xa3o', 'sei', 'se', 'est\xc3\xa1', 'funcionando', '.']]
>>> rubt.batch_tag(codificada)
[[('N\xc3\xa3o', 'NEG'), ('sei', 'VB-P'), ('se', 'WQ'), ('est\xc3\xa1', 'ET-P'), ('funcionando', 'VB-G'), ('.', '.')]]
>>> from Aelius.AnotaCorpus import anota_sentencas
>>> from Aelius.Extras import carrega
>>> from Aelius.Toqueniza import TOK_PORT_MM as tok
>>> from Aelius.AnotaCorpus import extrai_corpus
>>> leitor_de_corpus=extrai_corpus("actg.txt")
>>> sents=leitor_de_corpus.sents()
>>> print sents[3]
[u'O', u'objetivo', u'central', u'deste', u'livro', u'\xe9', u'preencher', u'a', u'lacuna', u'existente', u'de', u'obras', u'que', u'explorem', u',', u'de', u'forma', u'mais', u'aprofundada', u',', u'a', u'aplica\xe7\xe3o', u'computacional', u'de', u'pesquisas', u'em', u'sintaxe', u'formal', u'.']
>>> tokens=sents[3]
>>> mxpost=carrega("AeliusMaxEntMM")
>>> sentencas_anotadas=anota_sentencas([tokens],mxpost,"mxpost",separacao_contracoes=True)
>>> for w,t in sentencas_anotadas[0]:
print "%s/%s " % (w,t),
O/ART objetivo/N central/ADJ de/PREP|+ este/PROADJ livro/N é/V preencher/V a/ART lacuna/N existente/ADJ de/PREP obras/N que/PRO-KS-REL explorem/V ,/, de/PREP forma/N mais/ADV aprofundada/PCP ,/, a/ART aplicação/N computacional/ADJ de/PREP pesquisas/N em/PREP sintaxe/N formal/ADJ ./.
>>> mxpost_tycho=carrega("AeliusMaxEnt")
>>> sentencas_anotadas=anota_sentencas([tokens],mxpost_tycho,"mxpost")
>>> for w,t in sentencas_anotadas[0]:
print "%s/%s " % (w,t),
O/D objetivo/ADJ central/N deste/P+D livro/N é/SR-P preencher/VB a/D-F lacuna/N existente/ADV de/P obras/N-P que/WPRO explorem/VB-SP ,/, de/P forma/N mais/ADV-R aprofundada/VB-AN-F ,/, a/D-F aplicação/N computacional/ADJ-G de/P pesquisas/N-P em/P sintaxe/N formal/ADJ-G ./.
>>> leitor_de_corpus=extrai_corpus("actg.txt",toquenizador_vocabular=tok)
>>> hunpos=carrega("AeliusHunPosMM")
>>> sents=leitor_de_corpus.sents()
>>> print sents[3]
[u'O', u'objetivo', u'central', u'deste', u'livro', u'\xe9', u'preencher', u'a', u'lacuna', u'existente', u'de', u'obras', u'que', u'explorem', u',', u'de', u'forma', u'mais', u'aprofundada', u',', u'a', u'aplica\xe7\xe3o', u'computacional', u'de', u'pesquisas', u'em', u'sintaxe', u'formal', u'.']
>>> tokens=sents[3]
>>> sentencas_anotadas=anota_sentencas([tokens],hunpos,"hunpos",separacao_contracoes=True)
>>> for w,t in sentencas_anotadas[0]:
print "%s/%s " % (w,t),
O/ART objetivo/N central/ADJ de/PREP|+ este/PROADJ livro/N é/VAUX preencher/V a/ART lacuna/N existente/ADJ de/PREP obras/N que/PRO-KS-REL explorem/V ,/, de/PREP forma/N mais/ADV aprofundada/PCP ,/, a/ART aplicação/N computacional/ADJ de/PREP pesquisas/N em/PREP sintaxe/N formal/ADJ ./.
>>> from Aelius.AnotaCorpus import anota_sentencas
>>> from Aelius.Extras import carrega
>>> from Aelius.Toqueniza import TOK_PORT_LX2 as tok
>>> from Aelius.AnotaCorpus import extrai_corpus
>>> leitor_de_corpus=extrai_corpus("actg.txt",toquenizador_vocabular=tok)
>>> sents=leitor_de_corpus.sents()
>>> print sents[3]
[u'O', u'objetivo', u'central', u'deste', u'livro', u'\xe9', u'preencher', u'a', u'lacuna', u'existente', u'de', u'obras', u'que', u'explorem', u',', u'de', u'forma', u'mais', u'aprofundada', u',', u'a', u'aplica\xe7\xe3o', u'computacional', u'de', u'pesquisas', u'em', u'sintaxe', u'formal', u'.']
>>> tokens=sents[3]
>>> lxtagger=carrega("lxtagger")
>>> sentencas_anotadas=anota_sentencas([tokens],lxtagger,"mxpost",separacao_contracoes=True)
>>> for w,t in sentencas_anotadas[0]:
print "%s/%s " % (w,t),
O/DA objetivo/CN central/ADJ de/PREP este/DEM livro/CN é/V preencher/INF a/DA lacuna/CN existente/ADJ de/PREP obras/CN que/REL explorem/V ,/PNT de/PREP forma/CN mais/ADV aprofundada/PPA ,/PNT a/DA aplicação/CN computacional/ADJ de/PREP pesquisas/CN em/PREP sintaxe/CN formal/ADJ ./PNT
>>> from Aelius.Toqueniza import TOK_PORT_MM as tok
>>> leitor_de_corpus=extrai_corpus("actg.txt",toquenizador_vocabular=tok)
>>> sents=leitor_de_corpus.sents()
>>> tokens=sents[3]
>>> opennlp="../MAC-MORPHO_TRAIN/AeliusMaxentOpenNLP.bin"
>>> sentencas_anotadas=anota_sentencas([tokens],opennlp,"opennlp",separacao_contracoes=True)
>>> for w,t in sentencas_anotadas[0]:
print "%s/%s " % (w,t),
O/ART objetivo/N central/ADJ de/PREP|+ este/PROADJ livro/N é/V preencher/V a/ART lacuna/N existente/ADJ de/PREP obras/N que/PRO-KS-REL explorem/V ,/, de/PREP forma/N mais/ADV aprofundada/PCP ,/, a/ART aplicação/N computacional/ADJ de/PREP pesquisas/N em/PREP sintaxe/N formal/ADJ ./.
>>> opennlp="../apache-opennlp-1.5.2-incubating/pt-pos-maxent.bin"
>>> sentencas_anotadas=anota_sentencas([tokens],opennlp,"opennlp",separacao_contracoes=True)
>>> for w,t in sentencas_anotadas[0]:
print "%s/%s " % (w,t),
O/art objetivo/n central/adj de/prp este/pron-det livro/n é/v-fin preencher/v-inf a/art lacuna/n existente/adj de/prp obras/n que/pron-indp explorem/v-fin ,/punc de/prp forma/n mais/adv aprofundada/v-pcp ,/punc a/art aplicação/n computacional/adj de/prp pesquisas/n em/prp sintaxe/n formal/adj ./punc
>>>
$ opennlp SentenceDetector pt-sent.bin < ~/aelius_data/exemplo.txt > exemplo-sent-tok.txt Loading Sentence Detector model ... done (0,077s) Average: 260,9 sent/s Total: 6 sent Runtime: 0.023s $ opennlp TokenizerME pt-token.bin < exemplo-sent-tok.txt > exemplo-tok.txt Loading Tokenizer model ... done (0,481s) Average: 68,2 sent/s Total: 9 sent Runtime: 0.132s $ opennlp POSTagger pt-pos-maxent.bin < exemplo-tok.txt > exemplo-pos.txt Loading POS Tagger model ... done (0,738s) Average: 42,3 sent/s Total: 9 sent Runtime: 0.213s $ cat exemplo-pos.txt O_art excerto_adj abaixo_n contém_v-fin os_art dois_num primeiros_adj parágrafos_n do_v-pcp romance_n "Luzia-Homem"_prop (_punc Rio_prop de_prp Janeiro_n ,_punc 1903_num )_punc ,_punc de_prp Domingos_prop Olímpio_punc ,_punc nascido_v-pcp em_prp Sobral_prop ,_punc Ceará_prop ,_punc em_prp 18_num de_prp setembro_n de_prp 1850_num e_conj-c falecido_v-pcp no_adj Rio_prop de_prp Janeiro_n em_prp 6_num de_prp outubro_n de_prp 1906_num ._punc O_art texto_n ,_punc extraído_v-pcp do_v-pcp site_n Wikisource_prop ,_punc foi_v-fin revisado_v-pcp por_prp Leonel_prop F_prop ._punc de_prp Alencar_prop ._punc O_art morro_n do_v-ger Curral_prop do_v-pcp Açougue_prop emergia_n em_prp suave_n declive_v-fin da_v-pcp campina_n ondulada_v-pcp ._punc Escorchado_prop ,_punc indigente_adv de_prp arvoredo_n ,_punc o_art cômoro_n enegrecido_v-pcp pelo_adv sangue_n de_prp reses_n sem_prp conto_n ,_punc deixara_v-fin de_prp ser_v-inf o_art sítio_n sinistro_adj do_v-ger matadouro_n e_conj-c a_art pousada_n predileta_adj de_prp bandos_n de_prp urubutingas_n e_conj-c camirangas_n vorazes_adj ._punc Bateram-se_prop os_art vastos_n currais_adj ,_punc de_prp grossos_n esteios_pron-det de_prp aroeira_n ,_punc fincados_v-pcp a_prp pique_n ,_punc rijos_n como_adv barras_n de_prp ferro_n ,_punc currais_adj seculares_adj ,_punc obra_n ciclópica_adj ,_punc da_v-pcp qual_pron-det restava_v-fin apenas_adv ,_punc como_adv lúgubre_v-fin vestígio_n ,_punc o_art moirão_n ligeiramente_adv inclinado_v-pcp ,_punc adelgaçado_v-pcp no_adj centro_n ,_punc polido_n pelo_adv contínuo_v-fin atrito_v-pcp das_v-pcp cordas_n de_prp laçar_v-inf as_art vítimas_n ,_punc que_pron-indp a_prp ele_pron-pers eram_v-fin arrastadas_v-pcp aos_art empuxões_n ,_punc bufando_v-ger ,_punc resistindo_v-ger ,_punc ou_conj-c entregando_adv ,_punc resignadas_v-pcp e_conj-c mansas_adj ,_punc o_art pescoço_n à_pp faca_v-fin do_num magarefe_n ._punc Ali_adv ,_punc no_adj sítio_n de_prp morte_n ,_punc fervilhavam_v-fin ,_punc então_adv ,_punc em_prp ruidosa_adj diligência_n ,_punc legiões_n de_prp operários_n construindo_v-ger a_art penitenciária_n de_prp Sobral_prop ._punc
>>> from Aelius.AnotaCorpus import anota_texto
>>> from Aelius.Toqueniza import TOK_PORT_MM as tok
>>> from Aelius.Extras import carrega
>>> texto=Extras.carrega("exemplo.txt")
>>> import os
>>> raiz,nome=os.path.split(texto)
>>> opennlp="../apache-opennlp-1.5.2-incubating/pt-pos-maxent.bin"
>>> AnotaCorpus.INFIXO=os.path.split(opennlp)[1]
>>> anota_texto(nome,opennlp,"opennlp",tok,raiz,separacao_contracoes=True)
Arquivo anotado:
exemplo.pt-pos-maxent.bin.txt
>>> import nltk
>>> leitor_de_corpus=nltk.corpus.TaggedCorpusReader(".","exemplo.pt-pos-maxent.bin.txt")
>>> sents_anotadas=leitor_de_corpus.tagged_sents()
>>> for sent in sents_anotadas:
for w,t in sent:
print "%s_%s " % (w,t),
print
O_ART excerto_ADJ abaixo_N contém_V-FIN os_ART dois_NUM primeiros_ADJ parágrafos_N de_PRP o_ART romance_N "_PUNC Luzia-Homem_PROP "_PUNC (_PUNC Rio_PROP de_PRP Janeiro_N ,_PUNC 1903_NUM )_PUNC ,_PUNC de_PRP Domingos_PROP Olímpio_PUNC ,_PUNC nascido_V-PCP em_PRP Sobral_PROP ,_PUNC Ceará_PROP ,_PUNC em_PRP 18_NUM de_PRP setembro_N de_PRP 1850_NUM e_CONJ-C falecido_V-PCP em_PRP o_ART Rio_PROP de_PRP Janeiro_N em_PRP 6_NUM de_PRP outubro_N de_PRP 1906_NUM ._PUNC
O_ART texto_N ,_PUNC extraído_V-PCP de_PRP o_ART site_N Wikisource_PROP ,_PUNC foi_V-FIN revisado_V-PCP por_PRP Leonel_PROP F._PUNC de_PRP Alencar_PROP ._PUNC
O_ART morro_N de_PRP o_ART Curral_PROP de_PRP o_ART Açougue_PROP emergia_PUNC em_PRP suave_N declive_V-FIN de_PRP a_ART campina_N ondulada_V-PCP ._PUNC
Escorchado_PROP ,_PUNC indigente_ADV de_PRP arvoredo_N ,_PUNC o_ART cômoro_N enegrecido_V-PCP por_PRP o_ART sangue_N de_PRP reses_N sem_PRP conto_N ,_PUNC deixara_V-FIN de_PRP ser_V-INF o_ART sítio_N sinistro_ADJ de_PRP o_ART matadouro_N e_CONJ-C a_ART pousada_N predileta_ADJ de_PRP bandos_N de_PRP urubutingas_N e_CONJ-C camirangas_N vorazes_ADJ ._PUNC
Bateram_V-FIN se_PRON-PERS os_ART vastos_N currais_ADJ ,_PUNC de_PRP grossos_N esteios_PRON-DET de_PRP aroeira_N ,_PUNC fincados_V-PCP a_PRP pique_N ,_PUNC rijos_N como_ADV barras_N de_PRP ferro_N ,_PUNC currais_ADJ seculares_ADJ ,_PUNC obra_N ciclópica_ADJ ,_PUNC de_PRP a_ART qual_PRON-DET restava_V-FIN apenas_ADV ,_PUNC como_ADV lúgubre_V-FIN vestígio_N ,_PUNC o_ART moirão_N ligeiramente_ADV inclinado_V-PCP ,_PUNC adelgaçado_V-PCP em_PRP o_ART centro_N ,_PUNC polido_N por_PRP o_ART contínuo_N atrito_V-PCP de_PRP as_ART cordas_N de_PRP laçar_V-INF as_ART vítimas_N ,_PUNC que_PRON-INDP a_PRP ele_PRON-PERS eram_V-FIN arrastadas_V-PCP a_PRP os_ART empuxões_N ,_PUNC bufando_V-GER ,_PUNC resistindo_V-GER ,_PUNC ou_CONJ-C entregando_ADV ,_PUNC resignadas_V-PCP e_CONJ-C mansas_ADJ ,_PUNC o_ART pescoço_N a_PRP a_ART faca_N de_PRP o_ART magarefe_N ._PUNC
Ali_ADV ,_PUNC em_PRP o_ART sítio_N de_PRP morte_N ,_PUNC fervilhavam_V-FIN ,_PUNC então_ADV ,_PUNC em_PRP ruidosa_ADJ diligência_N ,_PUNC legiões_N de_PRP operários_N construindo_V-GER a_ART penitenciária_N de_PRP Sobral_PROP ._PUNC
>>>
>>> from Aelius import AnotaCorpus, Toqueniza, Extras
>>> texto="actg.txt"
>>> print open("actg.txt","rU").readlines()[:2]
['Abordagens Computacionais da Teoria da Gram\xc3\xa1tica. Organiza\xc3\xa7\xc3\xa3o: Leonel Figueiredo de Alencar e Gabriel de \xc3\x81vila Othero. Campinas: Mercado de Letras, 2012.\n', '\n']
>>> for linha in open("actg.txt","rU").readlines()[:3]:
print linha,
Abordagens Computacionais da Teoria da Gramática. Organização: Leonel Figueiredo de Alencar e Gabriel de Ávila Othero. Campinas: Mercado de Letras, 2012.
O objetivo central deste livro é preencher a lacuna existente de obras que explorem, de forma mais aprofundada, a aplicação computacional de pesquisas em sintaxe formal. Busca oferecer aos leitores de língua portuguesa um material teoricamente bem fundamentado e, ao mesmo tempo, de leitura acessível na área de interface entre gramática e computação, sob a perspectiva de alguns dos principais modelos linguísticos dos últimos 25 anos caracterizadas por um design computacional.
>>> macmorpho=Extras.carrega("AeliusHunPosMM")
>>> AnotaCorpus.anota_texto(texto,macmorpho,"hunpos",Toqueniza.TOK_PORT_MM,separacao_contracoes=True)
Arquivo anotado:
actg.hunpos.txt
>>> import nltk
>>> leitor_de_corpus=nltk.corpus.TaggedCorpusReader(".","actg.hunpos.txt")
>>> len(leitor_de_corpus.tagged_paras())
7
>>> sentencas_anotadas=leitor_de_corpus.tagged_sents()
>>> for w,t in sentencas_anotadas[0]:
print "%s/%s " % (w,t),
Abordagens/N Computacionais/ADJ de/PREP|+ a/ART Teoria/NPROP de/PREP|+ a/ART Gramática/N ./.
>>> tycho_brahe=Extras.carrega("AeliusHunPos")
>>> AnotaCorpus.INFIXO="tycho_hunpos"
>>> AnotaCorpus.anota_texto(texto,tycho_brahe,"hunpos",Toqueniza.TOK_PORT)
Arquivo anotado:
actg.tycho_hunpos.txt
>>> leitor_de_corpus=nltk.corpus.TaggedCorpusReader(".","actg.tycho_hunpos.txt")
>>> sentencas_anotadas=leitor_de_corpus.tagged_sents()
>>> for w,t in sentencas_anotadas[0]:
print "%s/%s " % (w,t),
Abordagens/N-P Computacionais/ADJ-G-P da/P+D-F Teoria/NPR da/P+D-F Gramática/NPR ./.
>>> for w,t in sentencas_anotadas[3]:
print "%s/%s " % (w,t),
O/D objetivo/N central/ADJ-G deste/P+D livro/N é/SR-P preencher/VB a/D-F lacuna/N existente/ADJ-G de/P obras/N-P que/WPRO explorem/VB-P ,/, de/P forma/N mais/ADV-R aprofundada/VB-AN-F ,/, a/D-F aplicação/N computacional/ADJ-G de/P pesquisas/N-P em/P sintaxe/N formal/ADJ-G ./.
>>>
>>> from Aelius import AnotaCorpus, Toqueniza, Extras >>> texto="actg.txt" >>> opennlp="../MAC-MORPHO_TRAIN/AeliusMaxentOpenNLP.bin" >>> reload(AnotaCorpus)>>> AnotaCorpus.anota_texto(texto,opennlp,"opennlp",Toqueniza.TOK_PORT_MM,separacao_contracoes=True) Arquivo anotado: actg.opennlp.txt >>> leitor_de_corpus=nltk.corpus.TaggedCorpusReader(".","actg.opennlp.txt") >>> sentencas_anotadas=leitor_de_corpus.tagged_sents() >>> for w,t in sentencas_anotadas[3]: print "%s/%s " % (w,t), O/ART objetivo/N central/ADJ de/PREP|+ este/PROADJ livro/N é/V preencher/V a/ART lacuna/N existente/ADJ de/PREP obras/N que/PRO-KS-REL explorem/V ,/, de/PREP forma/N mais/ADV aprofundada/PCP ,/, a/ART aplicação/N computacional/ADJ de/PREP pesquisas/N em/PREP sintaxe/N formal/ADJ ./. >>>
>>> opennlp="../MAC-MORPHO_TRAIN/AeliusMaxentOpenNLP.bin"
>>> AnotaCorpus.anota_texto(texto,opennlp,"opennlp",Toqueniza.TOK_PORT_MM,separacao_contracoes=True)
Arquivo anotado:
actg.opennlp.txt
>>> leitor_de_corpus=nltk.corpus.TaggedCorpusReader(".","actg.opennlp.txt")
>>> sentencas_anotadas=leitor_de_corpus.tagged_sents()
>>> for w,t in sentencas_anotadas[3]:
print "%s/%s " % (w,t),
O/ART objetivo/N central/ADJ de/PREP|+ este/PROADJ livro/N é/V preencher/V a/ART lacuna/N existente/ADJ de/PREP obras/N que/PRO-KS-REL explorem/V ,/, de/PREP forma/N mais/ADV aprofundada/PCP ,/, a/ART aplicação/N computacional/ADJ de/PREP pesquisas/N em/PREP sintaxe/N formal/ADJ ./.
>>> AnotaCorpus.INFIXO="opennlp_perceptron"
>>> opennlp="../MAC-MORPHO_TRAIN/AeliusPerceptronOpenNLP.bin"
>>> AnotaCorpus.anota_texto(texto,opennlp,"opennlp",Toqueniza.TOK_PORT_MM,separacao_contracoes=True)
Arquivo anotado:
actg.opennlp_perceptron.txt
>>> leitor_de_corpus=nltk.corpus.TaggedCorpusReader(".","actg.opennlp_perceptron.txt")
>>> sentencas_anotadas=leitor_de_corpus.tagged_sents()
>>> for w,t in sentencas_anotadas[3]:
print "%s/%s " % (w,t),
O/ART objetivo/N central/ADJ de/PREP|+ este/PROADJ livro/N é/V preencher/V a/ART lacuna/N existente/ADJ de/PREP obras/N que/PRO-KS-REL explorem/V ,/, de/PREP forma/N mais/ADV aprofundada/PCP ,/, a/ART aplicação/N computacional/ADJ de/PREP pesquisas/N em/PREP sintaxe/V formal/ADJ ./.
>>>
>>> from Aelius import AnotaCorpus,Toqueniza, Extras
>>> m=Extras.carrega("AeliusHunPosMM")
>>> import os
>>> os.chdir("../analises")
>>> t="actg.txt"
>>> AnotaCorpus.anota_texto(t,m,"hunpos",Toqueniza.TOK_PORT_MM,separacao_contracoes=True,formato="xml")
Arquivo anotado:
actg.hunpos.xml
>>>
<?xml version='1.0' encoding='UTF-8'?> <TEI><!-- TEI P5 header based on template created with EditiX http://www.editix.com/--> <teiHeader xml:lang="en"> <fileDesc> <titleStmt> <title>title of the resource</title> <author>author of the resource</author> <respStmt> <resp>compiled by</resp> <name>compiler's name</name> </respStmt> </titleStmt> <publicationStmt> <p>supply publication information</p> </publicationStmt> <sourceDesc> <p>supply information about the source</p> </sourceDesc> </fileDesc> </teiHeader> <text xml:lang="pt"> <body> <div n="1" type="chap"> <p n="1"> <s n="1"> <w type="N" xml:id="w1">Abordagens</w> <w type="ADJ" xml:id="w2">Computacionais</w> <w type="PREP|+" xml:id="w3">de</w> <w type="ART" xml:id="w4">a</w> <w type="NPROP" xml:id="w5">Teoria</w> <w type="PREP|+" xml:id="w6">de</w> <w type="ART" xml:id="w7">a</w> <w type="N" xml:id="w8">Gramática</w> <w type="." xml:id="w9">.</w> </s> <s n="2"> <w type="NPROP" xml:id="w10">Organização</w> <w type=":" xml:id="w11">:</w> <w type="NPROP" xml:id="w12">Leonel</w> <w type="NPROP" xml:id="w13">Figueiredo</w> <w type="NPROP" xml:id="w14">de</w> <w type="NPROP" xml:id="w15">Alencar</w> <w type="KC" xml:id="w16">e</w> <w type="NPROP" xml:id="w17">Gabriel</w> <w type="NPROP" xml:id="w18">de</w> <w type="NPROP" xml:id="w19">Ávila</w> <w type="NPROP" xml:id="w20">Othero</w> <w type="." xml:id="w21">.</w> </s> <s n="3"> <w type="NPROP" xml:id="w22">Campinas</w> <w type=":" xml:id="w23">:</w> <w type="NPROP" xml:id="w24">Mercado</w> <w type="NPROP" xml:id="w25">de</w> <w type="NPROP" xml:id="w26">Letras</w> <w type="," xml:id="w27">,</w> <w type="N|AP" xml:id="w28">2012</w> <w type="." xml:id="w29">.</w> </s> </p> <p n="2"> <s n="4"> <w type="ART" xml:id="w30">O</w> <w type="N" xml:id="w31">objetivo</w> <w type="ADJ" xml:id="w32">central</w> <w type="PREP|+" xml:id="w33">de</w> <w type="PROADJ" xml:id="w34">este</w> <w type="N" xml:id="w35">livro</w> <w type="VAUX" xml:id="w36">é</w> <w type="V" xml:id="w37">preencher</w> <w type="ART" xml:id="w38">a</w> <w type="N" xml:id="w39">lacuna</w> <w type="ADJ" xml:id="w40">existente</w> <w type="PREP" xml:id="w41">de</w> <w type="N" xml:id="w42">obras</w> <w type="PRO-KS-REL" xml:id="w43">que</w> <w type="V" xml:id="w44">explorem</w> <w type="," xml:id="w45">,</w> <w type="PREP" xml:id="w46">de</w> <w type="N" xml:id="w47">forma</w> <w type="ADV" xml:id="w48">mais</w> <w type="PCP" xml:id="w49">aprofundada</w> <w type="," xml:id="w50">,</w> <w type="ART" xml:id="w51">a</w> <w type="N" xml:id="w52">aplicação</w> <w type="ADJ" xml:id="w53">computacional</w> <w type="PREP" xml:id="w54">de</w> <w type="N" xml:id="w55">pesquisas</w> <w type="PREP" xml:id="w56">em</w> <w type="N" xml:id="w57">sintaxe</w> <w type="ADJ" xml:id="w58">formal</w> <w type="." xml:id="w59">.</w> </s> <s n="5"> <w type="N" xml:id="w60">Busca</w> <w type="V" xml:id="w61">oferecer</w> <w type="PREP|+" xml:id="w62">a</w> <w type="ART" xml:id="w63">os</w> <w type="N" xml:id="w64">leitores</w> <w type="PREP" xml:id="w65">de</w> <w type="N" xml:id="w66">língua</w> <w type="ADJ" xml:id="w67">portuguesa</w> <w type="ART" xml:id="w68">um</w> <w type="N" xml:id="w69">material</w> <w type="ADV" xml:id="w70">teoricamente</w> <w type="ADV" xml:id="w71">bem</w> <w type="PCP" xml:id="w72">fundamentado</w> <w type="KC" xml:id="w73">e</w> <w type="," xml:id="w74">,</w> <w type="PREP|+" xml:id="w75">a</w> <w type="ART" xml:id="w76">o</w> <w type="PROADJ" xml:id="w77">mesmo</w> <w type="N" xml:id="w78">tempo</w> <w type="," xml:id="w79">,</w> <w type="PREP" xml:id="w80">de</w> <w type="N" xml:id="w81">leitura</w> <w type="ADJ" xml:id="w82">acessível</w> <w type="PREP|+" xml:id="w83">em</w> <w type="ART" xml:id="w84">a</w> <w type="N" xml:id="w85">área</w> <w type="PREP" xml:id="w86">de</w> <w type="N" xml:id="w87">interface</w> <w type="PREP" xml:id="w88">entre</w> <w type="N" xml:id="w89">gramática</w> <w type="KC" xml:id="w90">e</w> <w type="N" xml:id="w91">computação</w> <w type="," xml:id="w92">,</w> <w type="PREP" xml:id="w93">sob</w> <w type="ART" xml:id="w94">a</w> <w type="N" xml:id="w95">perspectiva</w> <w type="PREP" xml:id="w96">de</w> <w type="PROSUB" xml:id="w97">alguns</w> <w type="PREP|+" xml:id="w98">de</w> <w type="ART" xml:id="w99">os</w> <w type="ADJ" xml:id="w100">principais</w> <w type="N" xml:id="w101">modelos</w> <w type="ADJ" xml:id="w102">linguísticos</w> <w type="PREP|+" xml:id="w103">de</w> <w type="ART" xml:id="w104">os</w> <w type="ADJ" xml:id="w105">últimos</w> <w type="NUM" xml:id="w106">25</w> <w type="N" xml:id="w107">anos</w> <w type="PCP" xml:id="w108">caracterizadas</w> <w type="PREP" xml:id="w109">por</w> <w type="ART" xml:id="w110">um</w> <w type="N|EST" xml:id="w111">design</w> <w type="ADJ" xml:id="w112">computacional</w> <w type="." xml:id="w113">.</w> </s> </p> </div> </body> </text> </TEI>
Taggers trained on a contemporary newspaper corpus reveal less than 95% accuracy in tagging a small sample of early 20th century litterary prose (first two paragraphs of Domingos Olímpio's Luzia-Homem):
>>> from Aelius import Avalia
>>> import os
>>> os.chdir("../analises")
>>> from Aelius import Extras
>>> s=Extras.carrega("AeliusStanfordMM")
>>> h=Extras.carrega("AeliusHunPosMM")
>>> m=Extras.carrega("AeliusMaxEntMM")
>>> o="../MAC-MORPHO_TRAIN/AeliusPerceptronOpenNLP.bin"
>>> gold="luzia_inicio.macmorpho.gold.txt"
>>> Avalia.TestaEtiquetador(s,"stanford",ouro=gold)
Total de erros: 16
Total de palavras:170
Acurácia:90.588235
>>> Avalia.TestaEtiquetador(h,"hunpos",ouro=gold)
Total de erros: 9
Total de palavras:170
Acurácia:94.705882
>>> Avalia.TestaEtiquetador(m,"mxpost",ouro=gold)
Total de erros: 10
Total de palavras:170
Acurácia:94.117647
>>> Avalia.TestaEtiquetador(o,"opennlp",ouro=gold)
Total de erros: 17
Total de palavras:170
Acurácia:90.000000
>>> Avalia.VERBOSE=True
>>> Avalia.TestaEtiquetador(o,"opennlp",ouro=gold)
Total de erros: 17
Total de palavras:170
Acurácia:90.000000
>>> Avalia.exibe_erros()
Anotação automática Anotação humana
suave/PROADJ suave/ADJ
declive/N|EST declive/N
deixara/V deixara/VAUX
Bateram/V Bateram/V|+
se/KS se/PROPESS
vastos/N vastos/ADJ
currais/ADJ currais/N
grossos/N grossos/ADJ
esteios/ADJ esteios/N
a/ART a/PREP
rijos/N rijos/ADJ
a/PRO-KS-REL a/PROSUB
lúgubre/N lúgubre/ADJ
vestígio/ADJ vestígio/N
a/PREP|+ a/PREP
mansas/N mansas/ADJ
então/PDEN então/ADV
>>>
Accuracy of different taggers on the same sample above:
>>> h=Extras.carrega("AeliusHunPos")
>>> m=Extras.carrega("AeliusMaxEnt")
>>> gold="luzia_inicio.chptb.gold.txt"
>>> Avalia.TestaEtiquetador(h,"hunpos",ouro=gold)
Total de erros: 4
Total de palavras:158
Acurácia:97.468354
>>> Avalia.TestaEtiquetador(m,"mxpost",ouro=gold)
Total de erros: 6
Total de palavras:158
Acurácia:96.202532
Accuracy increases when these taggers are applied to a contemporary text (see aelius_data folder):
>>> gold=Extras.carrega("lipral.mm.gold.txt")
>>> import os
>>> raiz,nome=os.path.split(gold)
>>> s=Extras.carrega("AeliusStanfordMM")
>>> h=Extras.carrega("AeliusHunPosMM")
>>> m=Extras.carrega("AeliusMaxEntMM")
>>> o="../MAC-MORPHO_TRAIN/AeliusPerceptronOpenNLP.bin"
>>> om="../MAC-MORPHO_TRAIN/AeliusMaxentOpenNLP.bin"
>>> Avalia.TestaEtiquetador(s,"stanford",raiz=raiz,ouro=nome)
Total de erros: 51
Total de palavras:743
Acurácia:93.135935
>>> Avalia.TestaEtiquetador(h,"hunpos",raiz=raiz,ouro=nome)
Total de erros: 28
Total de palavras:743
Acurácia:96.231494
>>> Avalia.TestaEtiquetador(m,"mxpost",raiz=raiz,ouro=nome)
Total de erros: 29
Total de palavras:743
Acurácia:96.096904
>>> Avalia.TestaEtiquetador(o,"opennlp",raiz=raiz,ouro=nome)
Total de erros: 25
Total de palavras:743
Acurácia:96.635262
>>> Avalia.TestaEtiquetador(om,"opennlp",raiz=raiz,ouro=nome)
Total de erros: 39
Total de palavras:743
Acurácia:94.751009
>>>
>>> from Aelius import AnotaCorpus, Extras, Toqueniza, Chunking
>>> lx=Extras.carrega("lxtagger")
>>> tok=Toqueniza.TOK_PORT_LX2
>>> import os
>>> raiz, nome=os.path.split(Extras.carrega("actg.txt"))
>>> leitor_de_corpus=AnotaCorpus.extrai_corpus(nome,raiz,toquenizador_vocabular=tok)
>>> sents=leitor_de_corpus.sents()
>>> print sents[5]
[u'Na', u'Europa', u'e', u'nos', u'Estados', u'Unidos', u',', u'a', u'\xe1rea', u'da', u'Lingu\xedstica', u'Computacional', u'est\xe1', u'em', u'extrema', u'expans\xe3o', u'e', u'goza', u'de', u'muita', u'popularidade', u',', u'tanto', u'nos', u'cursos', u'de', u'Ci\xeancias', u'da', u'Computa\xe7\xe3o', u'quanto', u'nos', u'de', u'Lingu\xedstica', u'.']
>>> anotadas=AnotaCorpus.anota_sentencas([sents[5]],lx,"mxpost",separacao_contracoes=True)
>>> for w,t in anotadas[0]:
print "%s/%s " % (w,t),
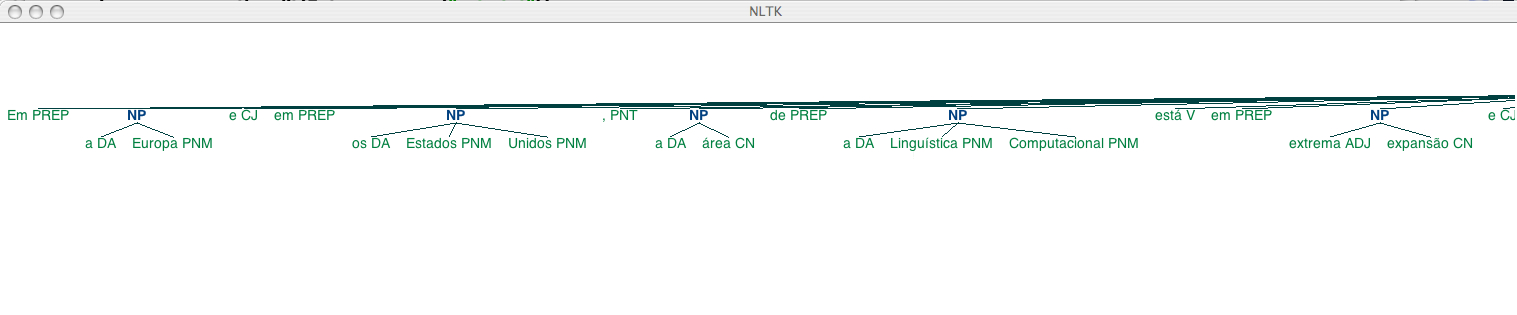
Em/PREP a/DA Europa/PNM e/CJ em/PREP os/DA Estados/PNM Unidos/PNM ,/PNT a/DA área/CN de/PREP a/DA Linguística/PNM Computacional/PNM está/V em/PREP extrema/ADJ expansão/CN e/CJ goza/CN de/PREP muita/QNT popularidade/CN ,/PNT tanto/ADV em/PREP os/DA cursos/CN de/PREP Ciências/PNM de/PREP a/DA Computação/CN quanto/REL nos/CL de/PREP Linguística/PNM ./PNT
>>> chunks=Chunking.CHUNKER.batch_parse(anotadas)
>>> chunks[0]
Tree('S', [(u'Em', u'PREP'), Tree('NP', [(u'a', u'DA'), (u'Europa', u'PNM')]), (u'e', u'CJ'), (u'em', u'PREP'), Tree('NP', [(u'os', u'DA'), (u'Estados', u'PNM'), (u'Unidos', u'PNM')]), (u',', u'PNT'), Tree('NP', [(u'a', u'DA'), (u'\xe1rea', u'CN')]), (u'de', u'PREP'), Tree('NP', [(u'a', u'DA'), (u'Lingu\xedstica', u'PNM'), (u'Computacional', u'PNM')]), (u'est\xe1', u'V'), (u'em', u'PREP'), Tree('NP', [(u'extrema', u'ADJ'), (u'expans\xe3o', u'CN')]), (u'e', u'CJ'), Tree('NP', [(u'goza', u'CN')]), (u'de', u'PREP'), Tree('NP', [(u'muita', u'QNT'), (u'popularidade', u'CN')]), (u',', u'PNT'), (u'tanto', u'ADV'), (u'em', u'PREP'), Tree('NP', [(u'os', u'DA'), (u'cursos', u'CN')]), (u'de', u'PREP'), Tree('NP', [(u'Ci\xeancias', u'PNM')]), (u'de', u'PREP'), Tree('NP', [(u'a', u'DA'), (u'Computa\xe7\xe3o', u'CN')]), (u'quanto', u'REL'), (u'nos', u'CL'), (u'de', u'PREP'), Tree('NP', [(u'Lingu\xedstica', u'PNM')]), (u'.', u'PNT')])
>>> chunks[0].draw()
>>> import nltk
>>> iob=nltk.chunk.tree2conllstr(chunks[0])
>>> iob
u'Em PREP O\na DA B-NP\nEuropa PNM I-NP\ne CJ O\nem PREP O\nos DA B-NP\nEstados PNM I-NP\nUnidos PNM I-NP\n, PNT O\na DA B-NP\n\xe1rea CN I-NP\nde PREP O\na DA B-NP\nLingu\xedstica PNM I-NP\nComputacional PNM I-NP\nest\xe1 V O\nem PREP O\nextrema ADJ B-NP\nexpans\xe3o CN I-NP\ne CJ O\ngoza CN B-NP\nde PREP O\nmuita QNT B-NP\npopularidade CN I-NP\n, PNT O\ntanto ADV O\nem PREP O\nos DA B-NP\ncursos CN I-NP\nde PREP O\nCi\xeancias PNM B-NP\nde PREP O\na DA B-NP\nComputa\xe7\xe3o CN I-NP\nquanto REL O\nnos CL O\nde PREP O\nLingu\xedstica PNM B-NP\n. PNT O'
>>> print iob
Em PREP O
a DA B-NP
Europa PNM I-NP
e CJ O
em PREP O
os DA B-NP
Estados PNM I-NP
Unidos PNM I-NP
, PNT O
a DA B-NP
área CN I-NP
de PREP O
a DA B-NP
Linguística PNM I-NP
Computacional PNM I-NP
está V O
em PREP O
extrema ADJ B-NP
expansão CN I-NP
e CJ O
goza CN B-NP
de PREP O
muita QNT B-NP
popularidade CN I-NP
, PNT O
tanto ADV O
em PREP O
os DA B-NP
cursos CN I-NP
de PREP O
Ciências PNM B-NP
de PREP O
a DA B-NP
Computação CN I-NP
quanto REL O
nos CL O
de PREP O
Linguística PNM B-NP
. PNT O
>>>
>>> from Aelius import Extras, Toqueniza, AnotaCorpus, Chunking
>>> import os
>>> raiz,nome=os.path.split(Extras.carrega("actg.txt"))
>>> lx=Extras.carrega("lxtagger")
>>> os.chdir("../analises")
>>> AnotaCorpus.anota_texto(nome,lx,"mxpost",toquenizador=Toqueniza.TOK_PORT_LX2,raiz=raiz,separacao_contracoes=True)
Arquivo anotado:
actg.mxpost.txt
>>> Chunking.CriaChunkedCorpus(".","actg.mxpost.txt")
>>> s=open("actg.mxpost.trees.txt","rU").read().strip().split("\n\n")
>>> s[0]
'(S\n (NP\n Abordagens/PNM\n Computacionais/PNM\n de/PREP\n a/DA\n Teoria/PNM\n de/PREP\n a/DA\n Gram\xc3\xa1tica/PNM)\n ./PNT)'
>>> print s[0]
(S
(NP
Abordagens/PNM
Computacionais/PNM
de/PREP
a/DA
Teoria/PNM
de/PREP
a/DA
Gramática/PNM)
./PNT)
>>> print s[5]
(S
Em/PREP
(NP a/DA Europa/PNM)
e/CJ
em/PREP
(NP os/DA Estados/PNM Unidos/PNM)
,/PNT
(NP a/DA área/CN)
de/PREP
(NP a/DA Linguística/PNM Computacional/PNM)
está/V
em/PREP
(NP extrema/ADJ expansão/CN)
e/CJ
(NP goza/CN)
de/PREP
(NP muita/QNT popularidade/CN)
,/PNT
tanto/ADV
em/PREP
(NP os/DA cursos/CN)
de/PREP
(NP Ciências/PNM)
de/PREP
(NP a/DA Computação/CN)
quanto/REL
nos/CL
de/PREP
(NP Linguística/PNM)
./PNT)
>>> from nltk import Tree
>>> Tree.parse(s[5])
Tree('S', ['Em/PREP', Tree('NP', ['a/DA', 'Europa/PNM']), 'e/CJ', 'em/PREP', Tree('NP', ['os/DA', 'Estados/PNM', 'Unidos/PNM']), ',/PNT', Tree('NP', ['a/DA', '\xc3\xa1rea/CN']), 'de/PREP', Tree('NP', ['a/DA', 'Lingu\xc3\xadstica/PNM', 'Computacional/PNM']), 'est\xc3\xa1/V', 'em/PREP', Tree('NP', ['extrema/ADJ', 'expans\xc3\xa3o/CN']), 'e/CJ', Tree('NP', ['goza/CN']), 'de/PREP', Tree('NP', ['muita/QNT', 'popularidade/CN']), ',/PNT', 'tanto/ADV', 'em/PREP', Tree('NP', ['os/DA', 'cursos/CN']), 'de/PREP', Tree('NP', ['Ci\xc3\xaancias/PNM']), 'de/PREP', Tree('NP', ['a/DA', 'Computa\xc3\xa7\xc3\xa3o/CN']), 'quanto/REL', 'nos/CL', 'de/PREP', Tree('NP', ['Lingu\xc3\xadstica/PNM']), './PNT'])
>>> print Tree.parse(s[5]).pprint()
(S
Em/PREP
(NP a/DA Europa/PNM)
e/CJ
em/PREP
(NP os/DA Estados/PNM Unidos/PNM)
,/PNT
(NP a/DA área/CN)
de/PREP
(NP a/DA Linguística/PNM Computacional/PNM)
está/V
em/PREP
(NP extrema/ADJ expansão/CN)
e/CJ
(NP goza/CN)
de/PREP
(NP muita/QNT popularidade/CN)
,/PNT
tanto/ADV
em/PREP
(NP os/DA cursos/CN)
de/PREP
(NP Ciências/PNM)
de/PREP
(NP a/DA Computação/CN)
quanto/REL
nos/CL
de/PREP
(NP Linguística/PNM)
./PNT)
>>>
>>> help(AnotaCorpus.toqueniza_contracoes)
Help on function toqueniza_contracoes in module Aelius.AnotaCorpus:
toqueniza_contracoes(sentencas)
Esta função primeiro anota as sentenças com o TAGGER2, para depois utilizar seu output para separar as contrações.
>>> tokens1=AnotaCorpus.TOK_PORT.tokenize(AnotaCorpus.EXEMPLO)
>>> tokens1
[u'Os', u'candidatos', u'classificáveis', u'dos', u'cursos', u'de', u'Sistemas', u'de', u'Informação', u'poderão', u'ocupar', u'as', u'vagas', u'remanescentes', u'do', u'Curso', u'de', u'Engenharia', u'de', u'Software', u'.']
>>> AnotaCorpus.toqueniza_contracoes([tokens1])
[[u'Os', u'candidatos', u'classificáveis', u'de', u'os', u'cursos', u'de', u'Sistemas', u'de', u'Informação', u'poderão', u'ocupar', u'as', u'vagas', u'remanescentes', u'de', u'o', u'Curso', u'de', u'Engenharia', u'de', u'Software', u'.']]
>>>
>>> from Aelius import FreeLing
>>> from Aelius.Extras import carrega
>>> m=carrega("AeliusFreeLing")
>>> sent="O morro do Curral do Açougue emergia em suave declive da campina ondulada.".decode("utf-8")
>>> tok=FreeLing.FreeLingTokenizer()
>>> tokens=tok.tokenize(sent)
>>> tokens
[u'O', u'morro', u'de', u'o', u'Curral_de_o_A\xe7ougue', u'emergia', u'em', u'suave', u'declive', u'de', u'a', u'campina', u'ondulada', u'.']
>>> tagger=FreeLing.FreeLingTagger(m)
>>> sentenca_anotada=tagger.tag(tokens)
>>> sentenca_anotada
[('O', 'o', 'DA0MS0'), ('morro', 'morro', 'NCMS000'), ('de', 'de', 'SPS00'), ('o', 'o', 'DA0MS0'), ('Curral_de_o_A\xc3\xa7ougue', 'curral_de_o_a\xc3\xa7ougue', 'NP00000'), ('emergia', 'emergir', 'VMII3S0'), ('em', 'em', 'SPS00'), ('suave', 'suave', 'AQ0CS0'), ('declive', 'declive', 'NCMS000'), ('de', 'de', 'SPS00'), ('a', 'o', 'DA0FS0'), ('campina', 'campina', 'NCFS000'), ('ondulada', 'ondular', 'VMP00SF'), ('.', '.', 'Fp')]
>>> for token,lema,etiqueta in sentenca_anotada:
print "%s\t%s\t%s" % (token,lema,etiqueta)
O o DA0MS0
morro morro NCMS000
de de SPS00
o o DA0MS0
Curral_de_o_Açougue curral_de_o_açougue NP00000
emergia emergir VMII3S0
em em SPS00
suave suave AQ0CS0
declive declive NCMS000
de de SPS00
a o DA0FS0
campina campina NCFS000
ondulada ondular VMP00SF
. . Fp
>>>
